7 Ergebnisse
7.1 Wofür welcher Datensatz?
Für die meisten Auswertungen wird der Datensatz der Inhaltsanalyse schon reichen. Sie können damit beschreiben, in welchem Umfang welche Nachrichtenfaktoren vorkommen und welche Ausprägungen sie haben. Sie können auch testen, welche Nachrichtenfaktoren mit der journalistischen Beachtung (Platzierung und Umfang der Beiträge) in welchem Masse zusammenhängen (Kreuztabellen und Korrelationen). Sie können auch analysieren, wie die Nachrichtenfaktoren untereinander zusammenhängen und inwiefern sie in der Summe die journalistische Beachtung besser erklären als einzelne Nachrichtenfaktoren (Additivitätshypothese). Sie können auch untersuchen, ob bestimmte NF in Mediengruppen häufiger vorkommen und stärkere Durchschnittsintensitäten haben als in anderen. Mit den Daten der Inhaltsanalyse lassen sich also viele Hypothesen schon aufklären.
Was allein mit dem Datensatz der Inhaltsanalyse nicht geht, ist die Bedeutung der NF für die Aufmerksamkeit bzw. Erinnerung an Meldungen durch die Rezipienten. Dafür braucht es die Ergänzung durch die Erkenntnisse aus der Befragung. Darum werden die Nennungen von Meldungen an den Inhaltsanalysedatensatz angefügt, also die Datensätze fusioniert. Dann können Sie das, was Sie mit der journalistischen Beachtung gemacht haben, für die Nennungen der Meldungen wiederholen und vergleichen, welche NF für die journalistische Beachtung eine andere Rolle spielen als für die Rezipienten. Wenn Sie aus der Befragung noch Informationen haben, für wie wichtig oder interessant die Befragten die von ihnen genannten Meldungen finden oder worüber sich die Befragten mit anderen unterhalten haben, dann können Sie feststellen, welche NF mehr auf das Interesse abzielen und welche eher als wichtig empfunden werden und welche mitbestimmen, worüber man sich so unterhält (was also Gesprächswert hat). Mit dem fusionierten Datensatz, bei dem die Inhaltsanalyse primär ist und die Nennungen der Befragten angefügt wurden, können die meisten Hypothesen überprüft werden, da hier zum reinen IA-Datensatz noch die Informationen der Befragten hinzukommen.
Der Befragungsdatensatz alleine enthält nicht allzu viele Informationen. Die quasiexperimentellen Fragen, was für Schlagzeilen die Leute wie spannend finden, sind in der Regel nicht sehr ergiebig, weil sie eben nicht sehr valide sind (zu abstrakt und artifiziell). Die Befragung entfaltet ihren eigentlichen Wert erst mit der Datenfusion wie im vorherigen Abschnitt beschrieben. Allerdings haben Sie auch Daten über die Befragten, die dabei helfen können, die Befragten in Gruppen einzuteilen und dann zu schauen, welche Nachrichtenfaktoren bei diese Gruppen eine besondere Bedeutung haben. Dazu braucht es die Datenfusion der NF aus der Inhaltsanalyse an den Befragungsdatensatz. Dann haben sie für jeden Befragten, die durchschnittlichen Intensitäten (von 0 bis irgendwas) der Nachrichtenfaktoren, wie sie in den Meldungen vorkommen, die die Befragten genannt haben. Sie könnten also zB feststellen, ob ältere Befragte eher Meldungen mit anderen NF nennen als die jüngeren Befragte. Das wird vor allem spannend, wenn Sie die Nuter:innen von Medien unterteilen und schauen, ob vielleicht Promistatus oder individueller Schaden bei Leser:innen von Boulevard- oder reinen Onlinemedien besonders hoch im Kurs sind und bei SRF- oder NZZ-Nutzer:innen eine geringere Rolle spielen. Sie könnten sogar eine Faktorenanalyse der NF der Befragten durchführen und so herausfinden, welche Kombinationen von NF bei den Befragten stärker zusammenhängen. Und sie könnten explorativ eine Clusteranalyse durchführen und Gruppen von Befragten Bilden, die deutlich machen, dass es unterscheidbare Nutzer:innengruppen bei der Rezeption von Nachrichten gibt. Sie müssen nicht, aber Sie können das machen.
Manche AGs werden fast nur mit dem Datensatz arbeiten, der aus der Datenfusion von IA + Befragung entstanden ist (mit der IA alleine, werden viele Hypothesen ungeklärt bleiben, was natürlich nicht gut wäre). Da es Gruppen gibt, die Hypothesen darüber haben, wie sich die Bedeutung der NF zwischen Nutzer:innengruppen unterscheiden, brauchen die auch den Datensatz aus der Fusion Befragung + IA. Da ist die Fusion allerdings aufwendiger, fehleranfälliger und im Ergebnis mühsamer. Für das Zeitmanagement sollten alle AGs schon früh die vorbereinigten Daten aus der Befragung und der Inhaltsanalyse haben, um starten zu können. Wenn die Datenfusion IA + Befragung funktioniert hat und fertig ist, sollte die zur Verfügung gestellt werden. Als letztes sollten die fusionierten Daten aus Befragung + IA ausgegeben werden. Aus der stufenweisen Verteilung der Daten folgt, dass Datenaufbereitungen wiederholt werden müssen, also zB die Umkodierungen (mutate) und Labelei nochmals durchlaufen muss, die für die unfusionierten IA-Daten gemacht wurden, wenn die fusionierten Daten kommen. Das sollte allerdings kein Probleme sein, da diese Transformationen in R- oder Rmd-Dateien gespeichert sind und einfach nochmal durchlaufen müssen.
7.2 Stichprobenbeschreibung
Hier werden die Ergebnisse vor allem in Tabellenform präsentiert (Für ein Beispiel eines Verweises auf eine Tabelle siehe Tabelle 7.1). Im Unikontext sind Grafiken und Diagramme eher dann angebracht, wenn Tabellen weniger Informationen bereitstellen würden oder so unübersichtlich würden, dass man sie kaum noch lesen kann. Das ist im normalen Studium selten der Fall. Schöne Diagramme können eine Arbeit optisch aufwerten aber meistens nicht inhaltlich. Wenn Grafiken für die Ergebnisdarstellung genutzt werden, sollten immer die differenzierteren Tabellen im Anhang aufgeführt werden.
7.3 Häufigkeitstabelle mit Mehrfachantworten
Gerade in der Befragung haben Sie mehrere Fragen mit der Möglichkeit zu Mehrfachantworten. Das führt dann immer zu einem ganzen Set von Variablen, die immer eine 1 für “angekreuzt” enthalten und 0 für “nicht angekreuzt”. Wenn von solch einer Frage mit der Möglichkeit zu Mehrfachanworten eine Häufigkeitsauszählung gemacht werden soll, dann muss man aufpassen, worauf prozentuiert wird: auf die Anzahl der abgegebenen Antworten oder auf die Anzahl Fälle (im Fall, Befragte).
# mit dem Paket "ufs" recht einfach
DATEN_BF <- DATEN_BF |>
sjlabelled::var_labels(NACHRICHT_TITEL1 = "NZZ",
NACHRICHT_TITEL2 = "TA",
NACHRICHT_TITEL3 = "20 Minuten",
NACHRICHT_TITEL4 = "Blick",
NACHRICHT_TITEL5 = "Watson",
NACHRICHT_TITEL6 = "SRF News",
M112_20 = "Social Media",
M112_21 = "Google News",
M112_23 = "anderes"
)
DATEN_BF |>
select(NACHRICHT_TITEL1:NACHRICHT_TITEL6, M112_20, M112_21, M112_23) |> # hiermit die Variablen auswählen, die zu den Ausprägungen werden
sjlabelled::label_to_colnames() |> # hier werden die Label der Variablen zu den Zeilennamen
ufs::multiResponse() |> # produziert die Tabelle für die Merhfachantworten
rename("Medium" = "Option", # Hier werden die Spalten umbenannt
"n" = "Frequency",
"Prozent Antworten" = "Percentage of responses",
"Prozent Fälle" = "Percentage of (203) cases" # hier das "#" wegmachen, wenn Sie die richtige Anzahl statt "(203) cases" eingetragen haben
) |>
mutate(across(3:4, ~percent(.x/100,accuracy = 2))) |>
kableExtra::kable(caption = "Mediennuztung der Befragten",
booktabs = T,
align = c('l', 'r', 'r', 'r', 'r'), # wenn ab der zweiten Spalte alles rechtsbündig, dann geht auch rep("r", NCOL(employ_frq)-1)
linesep = "") |>
kableExtra::footnote(general = "Lesebeispiel: 34% der Befragten haben die NZZ genannt. Die NZZ macht 12% aller 544 Mediennennungen aus.",
general_title = "", # damit Kable unten nicht "Note" schreibt
threeparttable = T # damit längere Fussnoten umgebrochen werden
) |>
kableExtra::kable_styling()| Medium | n | Prozent Antworten | Prozent Fälle |
|---|---|---|---|
| NZZ | 67 | 12% | 34% |
| TA | 57 | 10% | 28% |
| 20 Minuten | 107 | 20% | 52% |
| Blick | 43 | 8% | 22% |
| Watson | 32 | 6% | 16% |
| SRF News | 79 | 14% | 38% |
| Social Media | 66 | 12% | 32% |
| Google News | 17 | 4% | 8% |
| anderes | 76 | 14% | 38% |
| Total | 544 | 100% | 268% |
| Lesebeispiel: 34% der Befragten haben die NZZ genannt. Die NZZ macht 12% aller 544 Mediennennungen aus. |
7.4 Vorkommen der NF
Es können am Anfang die wichtigsten Variablen für die Stichrpobenbeschreibung auch als einfache Häufigkeitsauszählungen dargestellt werden. Häufigkeitsauszählungen stellen die komplette Information einer Variablen dar, da jede mögliche Ausprägung wiedergegeben wird und ihre Anzahl im Datensatz. Das sind relativ viele Inoformationen. Wenn man das für mehrere Variablen macht, wird das viel Aufwand.
### Wenn Sie die Label bei der Datenaufbereitung schon vergeben haben, müssen Sie das hier natürlich nicht wiederholen
KNTR_frq <- DATEN_IA |> # baue eine Häufigkeitstabelle
select(KNTR) |> # nur KNTR auswählen
sjlabelled::as_label() |> # die Label verwenden
tidycomm::tab_frequencies(KNTR) |> # eine Häufigkeitstabelle erstellt wird
janitor::adorn_totals() |> # mit dieser Zeile können Sie eine Gesamtzeile unter Ihrer Tabelle einfügen
mutate(Prozent = paste0(as.character(round(percent * 100, 0)),"%")) |> # Wenn Sie Prozentangaben mit %-Zeichen möchten
select(1, n, Prozent) # hier nehmen wir von den Daten nur die erste Spalte 1 und die Fallzahl n und die Prozent
KNTR_frq |>
kableExtra::kable(caption = "Kontroverse",
booktabs = T,
align = c('l', rep('r',2)), # die 10 steht dafür, dass 10 weitere Spalten alle rechtsbündig sind bzw. wären
linesep = "", # ohne diese Zeile, macht knitr alle 5 Zeilen einen kleinen Abstand, der oft kaum Sinn macht
col.names = c("Kontroverse", "Häufigkeit", "Prozent"), # Damit können die Überschriften neu gemacht werden
) |> # noch mehr Anpassungsmöglichkeiten für kable finden Sie bei google: r kable
footnote(general = "Hier könnten/sollten Sie einen allgemeinen Hinweis oder eine kleine Erläuterung zur Tabelle geben.",
general_title = "", # damit Kable unten nicht "Note" schreibt
threeparttable = T # damit längere Fussnoten umgebrochen werden
) |>
kableExtra::kable_styling()| Kontroverse | Häufigkeit | Prozent |
|---|---|---|
| keine | 297 | 60% |
| gering | 145 | 29% |
| stark | 57 | 11% |
| Total | 499 | 100% |
| Hier könnten/sollten Sie einen allgemeinen Hinweis oder eine kleine Erläuterung zur Tabelle geben. |
rm(KNTR_frq) # Wird nicht mehr gebraucht und kann daher removed werden.Textbeispiel: In 60 Prozent der Onlinebeiträge kam der Nachrichtenfaktor “Kontroverse” nicht vor. In knapp einem Drittel der Artikel wurde eine “geringe” Kontroverse beschrieben. In 57 Artikeln von 499 wurde eine starke Kontroverse thematisiert (11%).
7.5 Vergleiche des Vorkommens
Da das einzelne Vorkommen von Nachrichtenfaktoren im Grunde nichts über ihre Bedeutung sagt, sollten das Vorkommen der NF verglichen werden. Da die Nachrichtenfaktoren aber in der Regel mit unterschiedlichen Ausprägungen gemessen wurden, müssen sie erstmal auf einen gemeinsamen Standard gebracht werden. Das geht zum Beispiel indem man sie in Dummyvariablen umwandelt, also immer dann eine 0 setzt, wenn ein NF nicht vorkam (Wert 0 im Datensatz) und 1, wenn er grösser war als 0, also 1, 2, 3 usw. Mit solchen Dummyvariablen kann man ganz gut rechnen. So ist der Mittelwert einer Dummyvariable gleich dem Proporz der 1er (Summe der 1 = Vorkommen der 1 dividiert durch die Anzahl). Wenn man das mal 100 rechnet, dann hat man die Prozentwerte.
## Hier die Label vergeben, die nachher im Säulendiagramm erscheinen sollen.
DATEN_IA <- DATEN_IA |>
sjlabelled::var_labels(PERS = "Personalisierung", KNTR = "Kontroverse", SCHAD = "Schaden", NAEHE = "Nähe")
DATEN_IA |>
select(PERS, KNTR, SCHAD, NAEHE, MEDIUM) |> # Auswahl Ihrer NFs
sjlabelled::label_to_colnames() |>
mutate(across(everything(), ~if_else(.x > 0, 1, 0))) |> # Hier alle gleich behandeln, indem alles was grösser als 0 zu 1 wird und alles andere zu 0 (Dummykodierung 0/1)
summarise(across(everything(), ~round(mean(.x, na.rm = TRUE),2)*100)) |> # Mittelwert von 0/1-Dummyvariablen * 100 ist Prozent, gerundet mit 0 Nachkommastellen
pivot_longer(cols = (everything()),
names_to = "NFs", values_to = "Prozent") |> # Die Tabelle muss noch ins Längsformat gebracht werden für das Balkendiagramm
ggplot(aes(NFs, Prozent)) + # ACHTUNG bei ggplot für die Diagramme wird das + verwendet und nicht |>
geom_col() +
geom_text(aes(label = paste0(format(Prozent), "%")), vjust = -.4) +
xlab("Nachrichtenfaktoren") 
Textbeispiel: Personalisierung kam in 78 Prozent der Artikel vor. Das bedeutet, dass Personalisierung für die Berichterstattung ein wichtiger Nachrichtenfaktor ist. Ohne Personen geht es offenbar nicht. Die “Nähe” der berichteten Ereignisse ist in 50 Prozent der Artikel gegeben. Das deutet darauf hin, dass die Belange von besonderer Bedeutung sind, die eine höhere Betroffenheit für die Schweizer Bevölkerung haben, weil sie in ihrere Nähe passieren. Medien berichten vor allem auch über Kontroversen oder kontroverse Themen. In der Stichprobe waren 40 Prozent der Artikel von Kontroversen geprägt. 38 Prozent der Artikel thematisierten einen “Schaden”. Das bedeutet einerseits, dass 62% der Artikel keinen Schaden thematisiert haben, also dennoch wichtig genug waren. Andererseits bedeutet das, dass Eregnisse mit der Thematisierung von Schäden häufig in den Medien aufgegriffen werden. Um die Bedeutung der NFs im Vergleich beurteilen zu können, muss noch untersucht werden, ob sie alleine stark genug sind, um einen hohen Nachrichtenwert zu begründen oder erst durch das Zusammenspiel mit anderen Nachrichtenfaktoren eine Rolle spielen.
7.6 Bedeutung der Nachrichtenfaktoren für die journalistische Selektion
DATEN_IA <- DATEN_IA |>
mutate(Nenn_Gr = rec(Nenn_Gesamt, rec = "1:3 = 1; 4:16 = 2; 17:100 = 3")) |>
sjlabelled::set_labels(Nenn_Gr, labels = (c("selten" = 1, "mittel" = 2, "häufig" = 3)))
# DATEN_IA |> frq(Nenn_Gr) Immer mal schnell checken mit frq, aber nie in den Output!
SCHAD_Nenn_KREUZ <- DATEN_IA |>
sjlabelled::as_label() |>
tidycomm::crosstab(SCHAD, Nenn_Gr, add_total = TRUE, percentages = TRUE, chi_square = TRUE) |> # Chi^2 finden sie in der Console und können es in die Fussnote kopieren
janitor::adorn_totals() |> # Wieder die Gesamtzeile
mutate(across(c(-1), ~paste0(as.character(round(.x * 100, 0)),"%"))) # Wenn Sie Prozentangaben mit %-Zeichen möchten
SCHAD_Nenn_KREUZ |> # Jetzt wird die Tabele noch hübsch gemacht
kableExtra::kable(caption = "Kreuztabelle für Schaden und Rezipienten-Nennungen", # ne Überschrift
booktabs = T, # das sorgt für gute Bücherqualitätstabellen
align = c('l', rep('r', NCOL(SCHAD_Nenn_KREUZ)-1)), # wenn ab der zweiten Spalte alles rechtsbündig, dann geht auch rep("r", NCOL(employ_frq)-1)
linesep = "", # ohne diese Zeile, macht knitr alle 5 Zeilen einen kleinen Abstand, der oft kaum Sinn macht
col.names = c("Nennungen", "keiner", "gering", "gross", "Gesamt"), # Damit können die Überschriften neu gemacht werden
) |> # noch mehr Anpassungsmöglichkeiten für kable finden Sie bei google: r kable
kableExtra::kable_styling() |> # hier können Sie stylen, aber bleiben Sie seriös :-)
kableExtra::footnote(general = "Hier könnten/sollten Sie einen allgemeinen Hinweis oder eine kleine Erläuterung zur Tabelle geben.",
general_title = "", # damit Kable unten nicht "Note" schreibt
threeparttable = T # damit längere Fussnoten umgebrochen werden
) |> add_header_above(c("", "Schaden" = 3, "")) |>
kableExtra::row_spec(4, bold = TRUE)| Nennungen | keiner | gering | gross | Gesamt |
|---|---|---|---|---|
| selten | 14% | 5% | 7% | 11% |
| mittel | 27% | 22% | 46% | 30% |
| häufig | 59% | 73% | 46% | 59% |
| Total | 100% | 100% | 100% | 100% |
| Hier könnten/sollten Sie einen allgemeinen Hinweis oder eine kleine Erläuterung zur Tabelle geben. |
Textbeispiel: Wenn Onlinebeiträge keinen Schaden aufweisen, werden sie am häufigsten von den Rezipienten nur selten genannt (14%). Nennungen mittlerer Häufigkeit korrespondieren am häufigsten mit grossem Schaden (46%). Die häufigsten Nennungen kommen dann zustande, wenn Meldungen einen geringen “Schadenswert” aufweisen. Das kann daran liegen, dass am häufigsten das Thema “Corona” genannt wurde, wo häufig zwar ein Schaden thematisiert wird, aber eher ein geringer. (Kreuztabellen sind schwer zu texten!)
7.6.1 Nachrichtenwert und Resonanz mehrerer Medien
Mit dieser Analyse wird die Bedeutung der Nachrichtenfaktoren für die Selektion durch verschiedene Medien untersucht. Der Grundgedanke baut darauf auf, dass Ereignisse mit einem sehr hohen Nachrichtenwert im Grunde in allen Medien aufgegriffen werden. Wir untersuchen hier also, ob über die thematisierten Ereignisse in wenigen oder vielen Medien berichtet wurde. Dazu fassen wir die kodierten Themen pro Tag zusammen und schauen, in wie vielen Medien sie aufgegriffen wurden.
SELEKT <- DATEN_IA |>
group_by(TC, TAG, MEDIUM) |> # Dieser Schritt ist notwendig, damit Merhfachthematisierungen eines Ereignisses pro Tag in einem Medium nur jeweils einmal gezählt werden
summarise(n = n(), # Anzahl der Themen pro Tag in einem Medium
PERS_m = max(PERS), # Hier werden die höchsten Werte je NF genommen, die an einem Tag in einem Medium zu jedem Thema gefunden wurden
KNTR_m = max(KNTR),
SCHAD_m = max(SCHAD),
NAEHE_m = max(NAEHE)) |>
group_by(TC,TAG) |> # Jetzt kann auf Tag aggregiert werden, weil oben jedes Thema pro Tag und Medium gezählt wurde
summarise(SELEKT = n(), # Anzahl der Medien, die die jeweiligen Themen aufgegriffen haben
Personalisierung = max(PERS_m), # Hier wird das Maximum des jeweiligen NF genommen, also das Maximum der kodierten NF-Stärke aller Medien
Kontroverse = max(KNTR_m),
Schaden = max(SCHAD_m),
Nähe = max(NAEHE_m)) |>
mutate(across(everything(), ~replace(.x, is.na(.x), 0))) |>
ungroup()
SELEKT |>
select(SELEKT:Nähe) |>
cor() |> # Hier wird wieder eine Tabelle mit kable produziert
kable(caption = "Korrelationen zwischen NFs", digits = 2,
booktabs = T,
align = c('rrrrr'), # die 5 steht für 5 Variablen
linesep = "", # ohne diese Zeile, macht knitr alle 5 Zeilen einen kleinen Abstand, der oft kaum Sinn macht
## col.names = c("Anstellung", "Lokal", "Regional", "National", "Transnational", "Gesamt"), # Damit können die Überschriften neu gemacht werden
) |> # noch mehr Anpassungsmöglichkeiten für kable finden Sie bei google: r kable
kableExtra::kable_styling() |> # hier können Sie stylen, aber bleiben Sie seriös :-)
footnote(general = "Hier könnten/sollten Sie einen allgemeinen Hinweis oder eine kleine Erläuterung zur Tabelle geben.",
general_title = "", # damit Kable unten nicht "Note" schreibt
threeparttable = T # damit längere Fussnoten umgebrochen werden
)| SELEKT | Personalisierung | Kontroverse | Schaden | Nähe | |
|---|---|---|---|---|---|
| SELEKT | 1.00 | 0.38 | 0.32 | 0.32 | 0.35 |
| Personalisierung | 0.38 | 1.00 | 0.20 | 0.23 | 0.27 |
| Kontroverse | 0.32 | 0.20 | 1.00 | 0.39 | 0.21 |
| Schaden | 0.32 | 0.23 | 0.39 | 1.00 | 0.31 |
| Nähe | 0.35 | 0.27 | 0.21 | 0.31 | 1.00 |
| Hier könnten/sollten Sie einen allgemeinen Hinweis oder eine kleine Erläuterung zur Tabelle geben. |
Textbeispiel: Untersucht man, wie stark die Nachrichtenfaktoren die Selektion der Themen über die Medien hinweg steuern, können relativ starke Korrelationen festgestellt werden. Die Korrelationen zwischen der Personalsierung und der Auswahl durch mehrere Medien ist mit .38 am stärksten.
Alternativ und vielleicht schöner kann das in einem Korrelationsplot dargestellt werden:
Corr_SELEKT <- SELEKT |>
select(SELEKT:Nähe) |>
cor()
Corr_SELEKT_test <- SELEKT |>
select(SELEKT:Nähe) |>
corrplot::cor.mtest(conf.level = .95)
corrplot::corrplot(Corr_SELEKT, p.mat = Corr_SELEKT_test$p,
type = "lower", method = "square",
addCoef.col = 'black',
insig = "pch", diag = FALSE ,
tl.cex=0.8, pch.cex = 0.8, tl.srt = 30)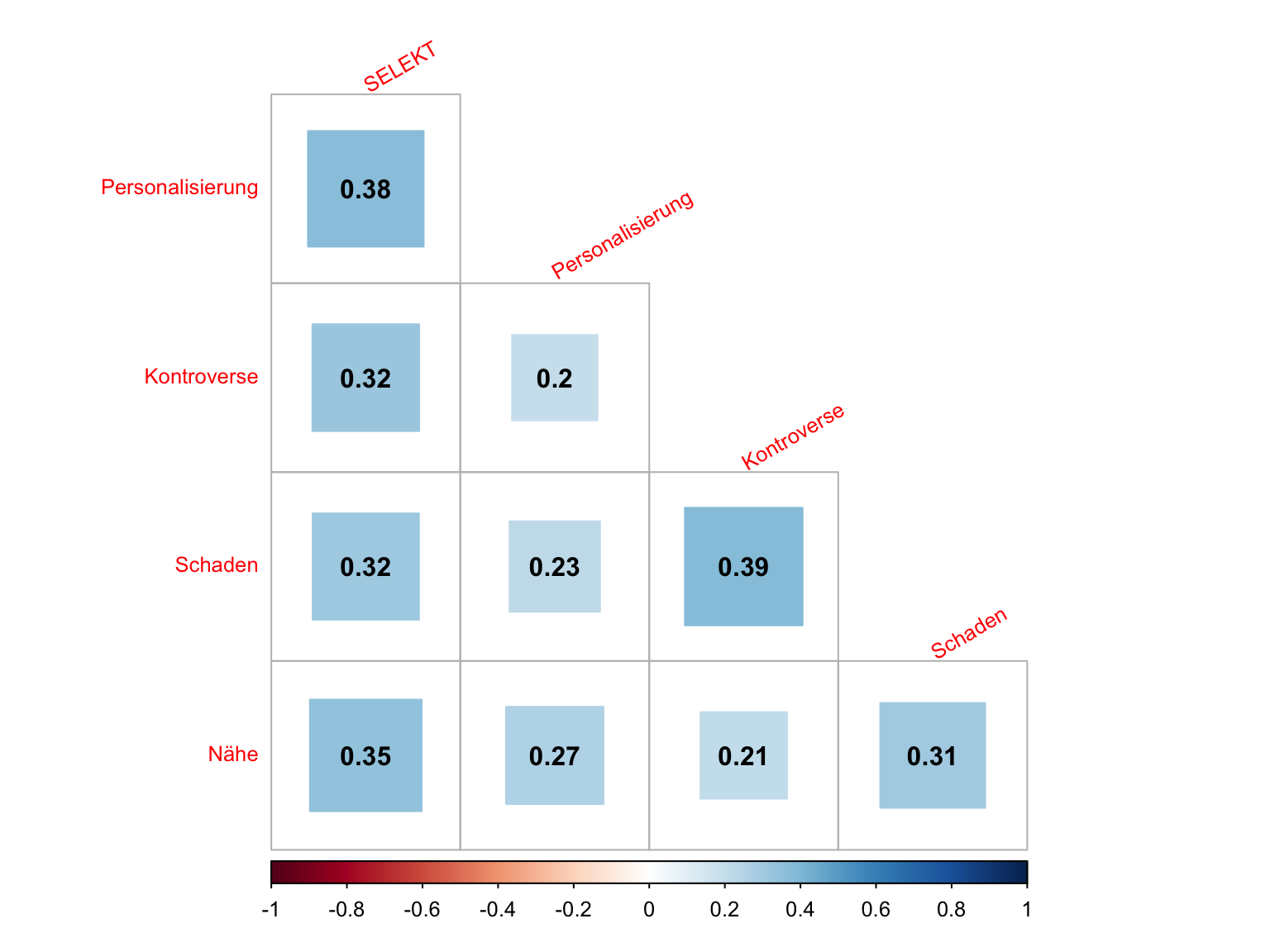
Abbildung 7.1: Korrelation der NFs mit der Anzahl der Medien, die über die Themen berichtet haben
rm(SELEKT,Corr_SELEKT, Corr_SELEKT_test)Textbeispiel: (wie oben mit Fokus auf die erste Spalte mit der Selektion)
7.7 Thematisierung in Medien und Publikumsresonanz
Wenn Sie eine Hypothese zum Zusammenhang zwischen der Häufigkeit eines Themas in den Medien und der Häufigkeit der Nennungen durch das Publikum haben oder zwischen der Stärke eines NF in der Berichterstattung und den Nennungen durch das Publikum, dann müssen Sie die Daten zunächst aggregieren, weil Ihre Analyseeinheit grösser ist als Ihre Kodiereinheit (CE). Das kommt daher, dass Sie nicht Eigenschaften von Beiträgen in Beziehung setzen wollen, sondern die Anzahl von Beiträgen der jeweiligen Themen in Verbindung setzen wollen mit den Nennungen des Publikums. Die Anzahl der Beiträge muss daher eine Aggregationsstufe über den Artikeln liegen.
DATEN_IA <- DATEN_IA |>
mutate(Nennungen = rowSums(across(Nenn1:Nenn5), na.rm = TRUE)) # hier nochmal zur Sicherheit die Nennungen insgesamt zählen über die Zeilensumme rowSum.
SELEKT <- DATEN_IA |>
group_by(TC) |> # Hier wird anhand der Themenvariable TC gruppiert
summarise(Them_n = n(), # Anzahl der Thematisierungen
PERS_m = max(PERS), # Hier werden die höchsten Werte je NF genommen, die zu jedem Thema gefunden wurden (Sie können auch mean probieren)
KNTR_m = max(KNTR),
SCHAD_m = max(SCHAD),
NAEHE_m = max(NAEHE),
Nenn_m = max(Nennungen)) |>
mutate(across(everything(), ~replace(.x, is.na(.x), 0))) |> # hier noch die na durch 0 ersetzen, weil "nicht gefunden" heisst 0 gefunden.
ungroup()
SELEKT |>
select(Them_n:Nenn_m) |>
cor() |> # Hier wird wieder eine Tabelle mit kable produziert
kableExtra::kable(caption = "Korrelationen zwischen Thematisierung und Nennungen durch das Publikum", digits = 2,
booktabs = T,
align = c('rrrrr'), # die 5 steht für 5 Variablen
linesep = "", # ohne diese Zeile, macht knitr alle 5 Zeilen einen kleinen Abstand, der oft kaum Sinn macht
## col.names = c("Them_n", "PERS_m", "KNTR_m", "SCHAD_m", "NAEHE_m", "Nenn_m"), # Damit können die Überschriften neu gemacht werden
) |> # noch mehr Anpassungsmöglichkeiten für kable finden Sie bei google: r kable
kableExtra::kable_styling() |> # hier können Sie stylen, aber bleiben Sie seriös :-)
kableExtra::footnote(general = "Hier könnten/sollten Sie einen allgemeinen Hinweis oder eine kleine Erläuterung zur Tabelle geben.",
general_title = "", # damit Kable unten nicht "Note" schreibt
threeparttable = T # damit längere Fussnoten umgebrochen werden
)| Them_n | PERS_m | KNTR_m | SCHAD_m | NAEHE_m | Nenn_m | |
|---|---|---|---|---|---|---|
| Them_n | 1.00 | 0.47 | 0.45 | 0.54 | 0.54 | 0.33 |
| PERS_m | 0.47 | 1.00 | 0.23 | 0.47 | 0.47 | 0.05 |
| KNTR_m | 0.45 | 0.23 | 1.00 | 0.33 | 0.34 | 0.10 |
| SCHAD_m | 0.54 | 0.47 | 0.33 | 1.00 | 0.54 | 0.07 |
| NAEHE_m | 0.54 | 0.47 | 0.34 | 0.54 | 1.00 | 0.07 |
| Nenn_m | 0.33 | 0.05 | 0.10 | 0.07 | 0.07 | 1.00 |
| Hier könnten/sollten Sie einen allgemeinen Hinweis oder eine kleine Erläuterung zur Tabelle geben. |
# auch hier können Sie natürlich die alternativen Correlationsdarstellungen nutzen7.8 Zusammenspiel der Nachrichtenfaktoren
Das Zusammenspiel der Nachrichtenfaktoren lässt sich als Kreuztabellen oder als Korrelationen darstellen. Wenn sehr wenige Nachrichtenfaktoren verglichen werden sollen, geben die Kreuztabellen einen differenzierteren Einblick. Bei mehreren NFs ist es deutlich effizienter die Stärke der Zusammenhänge über Korrelationen abzubilden.
Corr_NF <- DATEN_IA |>
select(PERS:NAEHE) |>
as.matrix() |>
cor()
Corr_NF_test <- DATEN_IA |>
select(PERS:NAEHE) |>
corrplot::cor.mtest(conf.level = .95)
# mehr zu den corrplots hier: https://cran.r-project.org/web/packages/corrplot/vignettes/corrplot-intro.html
corrplot::corrplot(Corr_NF, p.mat = Corr_NF_test$p,
type = "lower", method = "square",
insig = "pch", diag = FALSE ,
tl.cex=0.6, pch.cex = 0.8, tl.srt = 45)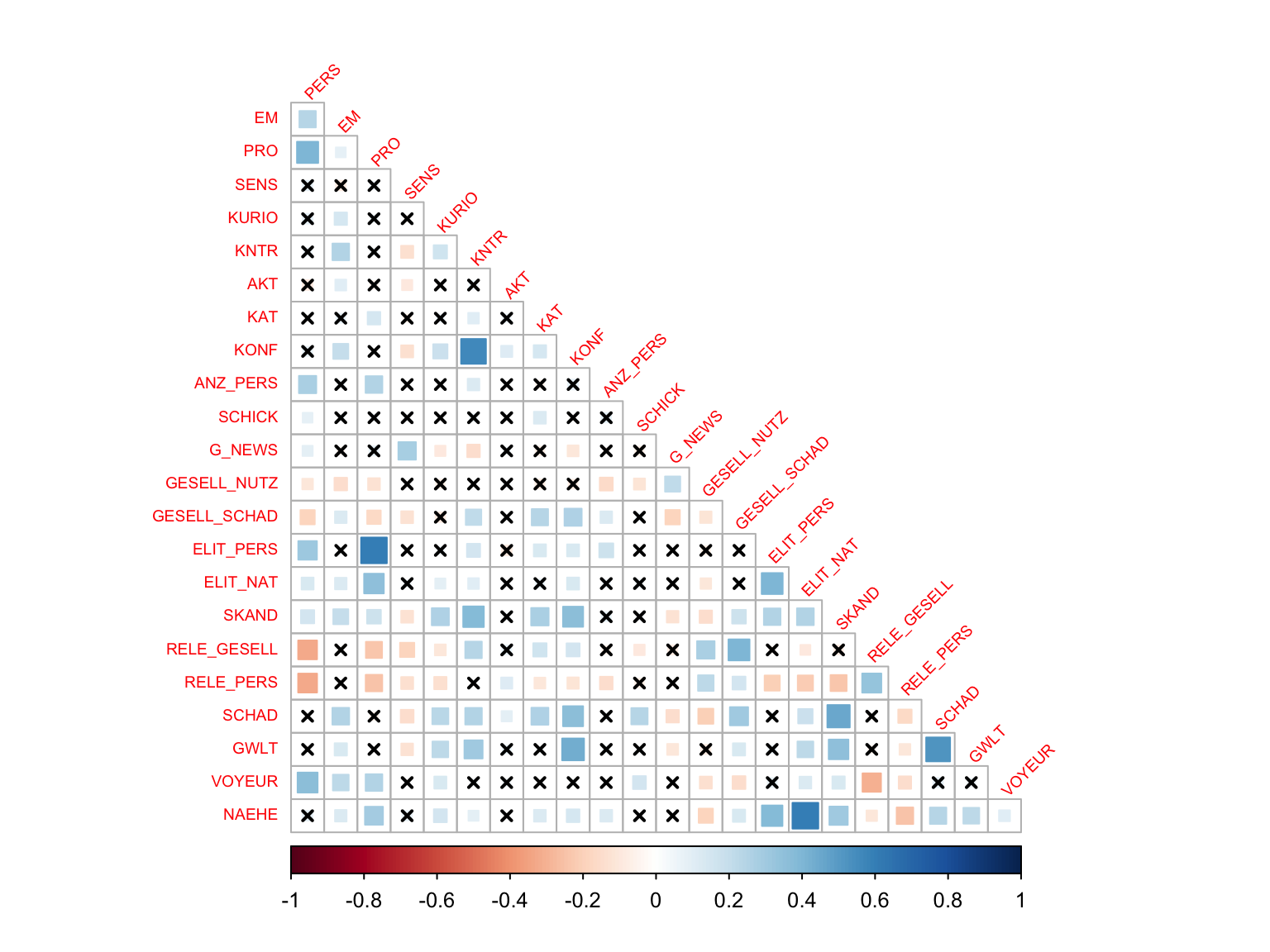
Textbeispiel: An den Korrelationen ist gut zu erkennen, dass manche Nachrichtenfaktoren eher zusammen auftreten, manche sich eher widersprechen und viele unabhängig voneinander sind (“x” im Feld für fehlende Signifikanz). Eine starke positive Korrellation findet sich zwischen “Elite-Personen” (ELIT_PERS) und “Prominenz” (PRO). Das ist sehr plausibel, weil Elitepersonen oft auch prominent sind. Auf der anderen Seite gibt es eine relativ starke negative Korrelation zwischen “gesellschaftlicher Relevanz” (RELE_GESELL) und “Personalisierung” (PERS). Themen mit gesellschaftlicher Relevanz sind also oft nicht personengebunden sondern von allgemeinerer und damit auch abstrakterer Natur.
7.8.1 Netzwerkplot der Korrelationen
Es gibt auch die Möglichkeit, die Nachrichtenfaktoren in so einem Netzwerkdiagramm darzustellen. Damit kann man sehen, welche Nachrichtenfaktoren stärker zusammenhängen (nahe beieinander) und welche eher unabhängig sind (weiter voneinander entfernt).
Corr_NF <- DATEN_IA |>
select(RELE_GESELL, RELE_PERS, PRO, PERS, KNTR, KONF, GESELL_SCHAD, GWLT, SCHAD) |>
corrr::correlate(diagonal = NA) # oder 1, wenn Sie lieber die 1er in der Diagonalen haben
Corr_NF |>
corrr::network_plot() # mehr zur Formatierung der network-plots erfahren Sie hier: https://corrr.tidymodels.org/reference/network_plot.html
Die näher beieinanderliegenden Nachrichtenfaktoren hängen stärker miteinander zusammen als die stärker entfernten. In diesem Netzwerkdiagramm ist gut zu erkennen, dass “Kontroverse” (KNTR), “Konflikt” (KONF), “Gewalt” (GWLT) und “Schaden” (SCHAD) stärker miteinander zusammenhängen als mit “Personalisierung” (PERS) oder “gesellschaftlicher Relevanz” (RELE_GESELL). Auf der anderen Seite gibt es eine relativ starke negative Korrelation zwischen “gesellschaftlicher Relevanz” (RELE_GESELL) und “Personalisierung” (PERS).
7.9 Wirkung der NF auf die Beachtungsindikatoren
7.9.1 Regressionstabellen
Beacht_Rez_1 <- lm(Nenn_Gesamt ~ PERS + KNTR + GESELL_SCHAD + Population, DATEN_IA)
Beacht_Jour_1 <- lm(Jour_Beacht ~ PERS + KNTR + GESELL_SCHAD + Population, DATEN_IA)
# mehr zu tab_model finden Sie hier: https://strengejacke.github.io/sjPlot/articles/tab_model_estimates.html
# Der Output erscheint rechts im Viewer und kann dort kopiert und zB nach Word übertragen werden.
sjPlot::tab_model(Beacht_Rez_1, Beacht_Jour_1, show.se = FALSE, show.std = TRUE, show.est = FALSE, p.style = "stars")| Nenn Gesamt | Jour Beacht | |||
|---|---|---|---|---|
| Predictors | std. Beta | standardized CI | std. Beta | standardized CI |
| (Intercept) | 0.00 | -0.09 – 0.09 | -0.00 | -0.07 – 0.07 |
| Personalisierung | -0.06 | -0.15 – 0.04 | 0.36 *** | 0.29 – 0.43 |
| Kontroverse | 0.04 | -0.05 – 0.14 | 0.09 * | 0.02 – 0.17 |
| GESELL SCHAD | 0.21 *** | 0.12 – 0.30 | 0.12 ** | 0.04 – 0.19 |
| Population | -0.05 | -0.14 – 0.04 | 0.43 *** | 0.36 – 0.51 |
| Observations | 463 | 463 | ||
| R2 / R2 adjusted | 0.058 / 0.050 | 0.390 / 0.385 | ||
|
||||
# Leider gibt es nur einen vollkommen unbrauchbaren Output im PDF also RMarkdown. Dafür gibt es aber Alternativen, die
# Wer noch mehr Kontrolle über die Tabelle möchte, kann sich mit lm.beta, tidy und kable austoben
Beacht_Rez_1_std <- lm.beta(Beacht_Rez_1)
# Damit können das R^2 und die Freiheitsgrade aus den Summarys des Modells extrahiert und gespeichert werden, damit man es später in der Fussnote des Modells verwenden kann.
R2 <- summary(Beacht_Rez_1_std)$r.squared
N <- summary(Beacht_Rez_1_std)$df[2]
tidy(Beacht_Rez_1_std) |>
select(-estimate, -std.error) |>
kable(caption = "Regression auf Beachtung der Rezipienten", digits = 2,
booktabs = T,
align = c('lrrrrrrrrr'), # die 5 steht für 5 Variablen
col.names = c("UVs", "BETAs", "t", "p"),
linesep = "", # ohne diese Zeile, macht knitr alle 5 Zeilen einen kleinen Abstand, der oft kaum Sinn macht
## col.names = c("Anstellung", "Lokal", "Regional", "National", "Transnational", "Gesamt"), # Damit können die Überschriften neu gemacht werden
) |> # noch mehr Anpassungsmöglichkeiten für kable finden Sie bei google: r kable
kable_styling() |> # hier können Sie stylen, aber bleiben Sie seriös :-)
footnote(general = paste0("$R^2$: ", round(R2, 2), " Freiheitsgrade: ", N, "\n Hier könnten/sollten Sie einen allgemeinen Hinweis oder eine kleine Erläuterung zur Tabelle geben."),
general_title = "", # damit Kable unten nicht "Note" schreibt
threeparttable = T # damit längere Fussnoten umgebrochen werden
)| UVs | BETAs | t | p |
|---|---|---|---|
| (Intercept) | — | 13.52 | 0.00 |
| PERS | -0.06 | -1.18 | 0.24 |
| KNTR | 0.04 | 0.92 | 0.36 |
| GESELL_SCHAD | 0.21 | 4.40 | 0.00 |
| Population | -0.05 | -1.10 | 0.27 |
|
\(R^2\): 0.06 Freiheitsgrade: 458 Hier könnten/sollten Sie einen allgemeinen Hinweis oder eine kleine Erläuterung zur Tabelle geben. |
Mit stargazer wird direkt LaTeX-Code erzeugt, der dann in den PDFs relativ schön angezeigt wird. Stargazer hat sehr viele Funktionen und kann sehr genau angepasst werden. Im HTML, wie auf dieser Seite, ist der Output nicht ganz so schön:
| Nenn_Gesamt | Jour_Beacht | |
| (1) | (2) | |
| PERS | -1.33*** (0.84) | 1.58 (0.15) |
| KNTR | 0.25 (0.95) | 0.54 (0.17) |
| GESELL_SCHAD | 7.50 (1.56) | 0.96 (0.28) |
| Constant | 18.67 (1.33) | 1.34 (0.24) |
| Observations | 499 | 499 |
| R2 | 0.06 | 0.21 |
| Note: | p<0.1; p<0.05; p<0.01 | |
Eine weitere Alternative ist jtools. Damit werden recht umfangreich Informationen über die Modelle inline in R-Studio ausgegeben und passabel im PDF rausgelassen. Nachteil ist die mässige bzw. umständliche Anpassbarkeit.
| Observations | 499 |
| Dependent variable | Nenn_Gesamt |
| Type | OLS linear regression |
| F(3,495) | 10.57 |
| R² | 0.06 |
| Adj. R² | 0.05 |
| Est. | 2.5% | 97.5% | t val. | p | VIF | |
|---|---|---|---|---|---|---|
| (Intercept) | 0.00 | -0.09 | 0.09 | 0.00 | 1.00 | — |
| PERS | -0.07 | -0.16 | 0.02 | -1.58 | 0.12 | 1.05 |
| KNTR | 0.01 | -0.08 | 0.10 | 0.27 | 0.79 | 1.06 |
| GESELL_SCHAD | 0.22 | 0.13 | 0.31 | 4.82 | 0.00 | 1.10 |
| Standard errors: OLS; Continuous variables are mean-centered and scaled by 1 s.d. |
Mehr dazu finden Sie hier.
##
##
## Regression results using Nenn_Gesamt as the criterion
##
##
## Predictor b b_95%_CI beta beta_95%_CI sr2 sr2_95%_CI r
## (Intercept) 18.67** [16.06, 21.29]
## PERS -1.33 [-2.98, 0.33] -0.07 [-0.16, 0.02] .00 [-.01, .02] -.11*
## KNTR 0.25 [-1.61, 2.12] 0.01 [-0.08, 0.10] .00 [-.00, .00] .06
## GESELL_SCHAD 7.50** [4.45, 10.56] 0.22 [0.13, 0.31] .04 [.01, .08] .24**
##
##
##
## Fit
##
##
##
##
## R2 = .060**
## 95% CI[.02,.10]
##
##
## Note. A significant b-weight indicates the beta-weight and semi-partial correlation are also significant.
## b represents unstandardized regression weights. beta indicates the standardized regression weights.
## sr2 represents the semi-partial correlation squared. r represents the zero-order correlation.
## Square brackets are used to enclose the lower and upper limits of a confidence interval.
## * indicates p < .05. ** indicates p < .01.
## 7.9.2 Regressionsdiagramm (Whyskerplot)
Tabellen sind einigermassen informativ. Besser lesbar ist allerdings die folgende Darstellung mit einem Whiskerplot, die auch sehr gut im PDF funktioniert, weil es eine Abbildung ist!
# mehr zu plot_models hier: https://strengejacke.github.io/sjPlot/articles/plot_model_estimates.html
sjPlot::plot_models(Beacht_Rez_1, Beacht_Jour_1,
std.est = "std", # Für die (vergleichbaren) standardisierten Regressionskoeffizienten
title = "NFs und Beachtung",
legend.title = "Beachtung",
show.values = TRUE) +
ylim(-.25, .6) # müssen Sie vielleicht anpassen. Der erste Wert muss kleiner sein als die kleinste Untergrenz eines CI und der zweite Wert grösser als die grösste Obergrenze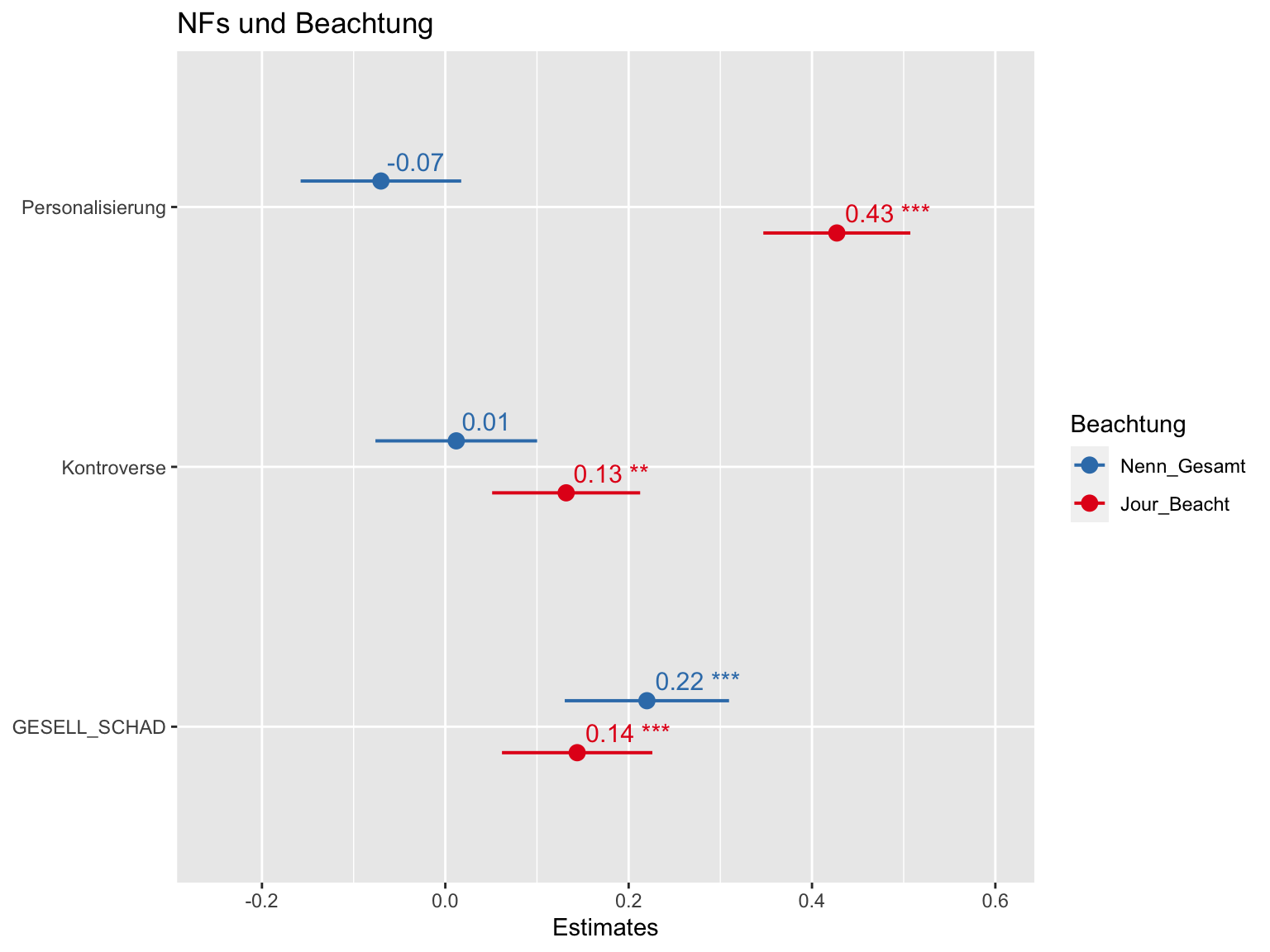
Abbildung 7.2: Nachrichtenfaktoren und Beachtung
Textbeispiel: “Personalisierung” wirkt auf die Beachtung durch Rezipipenten nur minimal und eher negativ (-.06). Insgesamt nennen die Befragten also etwas seltener Meldungen, wo die Personalisierung hohe Werte hat. Allerdings liegt 0 im Konfidenzintervall dieses kleinen Effekts; er ist also nicht signifikant. Im Unterschied dazu besteht ein starker positiver Zusammenhang zwischen der Personalisierung und der journalistischen Beachtung (.36). Personalisierung ist also ein stark journalistischer Nachrichtenfaktor.
Der Nachrichtenfaktor “Kontroverse” zeigt kleine positive Zusammenhäng mit der Beachtung durch die Rezipienten (.04) und mit der journalistischen Beachtung (.09). Allerdings ist die Wirkung auf die Rezipientenerinnerung nicht signifikant. Das Gewicht des Nachrichtenfaktors “Kontorverse” in Bezug auf die journalistische Beachtung ist signifikant von 0 verschieden.
7.10 Vergleich der NF-Gewichte nach Mediengruppen
Hier werden die NF-Gewichte nach Mediengruppe verglichen.
# mehr zu plot_models hier: https://strengejacke.github.io/sjPlot/articles/plot_model_estimates.html
Beacht_Quali_1 <- lm(Nenn_Gesamt ~ PERS + KNTR + GESELL_SCHAD + Population, subset(DATEN_IA, Medium_Q == 1))
Beacht_Boulevard_1 <- lm(Nenn_Gesamt ~ PERS + KNTR + GESELL_SCHAD + Population, subset(DATEN_IA, Medium_Q == 2))
sjPlot::plot_models(Beacht_Quali_1, Beacht_Boulevard_1,
std.est = "std", # Für die (vergleichbaren) standardisierten Regressionskoeffizienten
title = "Gewichte der NFs nach Medientypen",
legend.title = "Beachtung",
m.labels = c("Qualitätsmedien", "Boulevard"),
axis.title = "Regressionsgewichte",
show.values = TRUE) +
ylim(-.25, .6)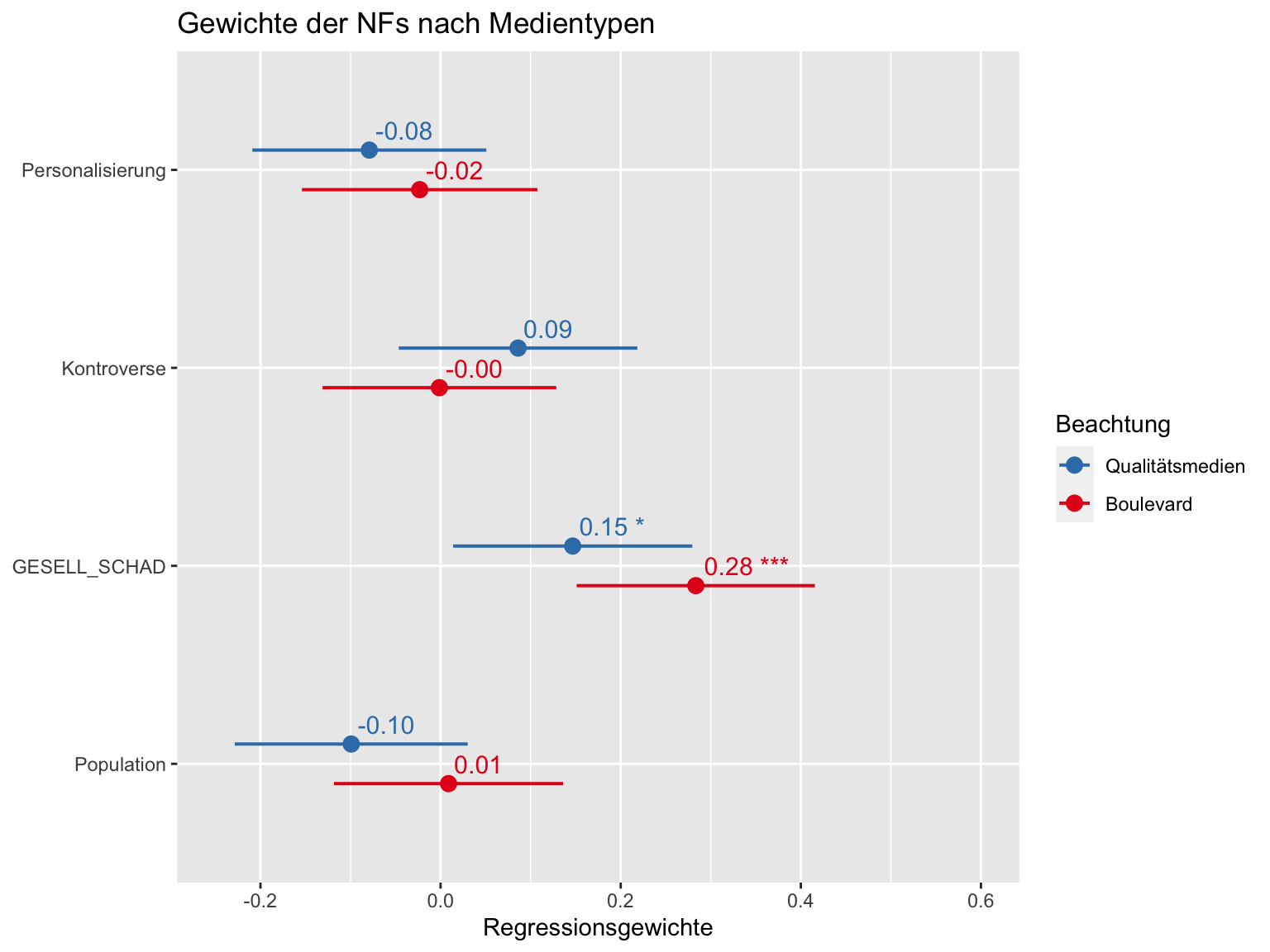
Abbildung 7.3: Nachrichtenfaktoren und Beachtung
7.11 Unterschiede der Gewichte von NF nach Befragtenmerkmalen
Zu diesen Auswertungen und den Voraussetzungen in der Datenaufbereitung habe ich noch ein Vidoe erstellt:
7.11.1 Zwei Gruppen als UV
Sie können Unterschiede in der Bedeutung (Gewicht) der Nachrichtenfaktoren mit eine Unterschiedstest untersuchen. Dazu müssen Sie die NF aus der Inhaltsanalyse an die Befragung matchen (siehe 5.2.2).
t_test <- t.test(KNTR_m ~ Geschlecht, DATEN_BF) # t-Test ausführen und in t_test schreiben
t_Wert <- round(t_test$statistic,2)
p_Wert <- round(t_test$p.value, 3)
df <- round(t_test$parameter,0)
### Hier werden die Werte aus dem t-Test in einen Text geschrieben, den Sie in einer Grafike als Annotation verwenden können
t_Test_Geschlecht_KNTR = paste0("t-Test: \n",
"p-Wert = ", p_Wert, # den p-Wert aus der t_test-List-Ausgabe
"\n (t = ", t_Wert, # den T-Wert (statistic) aus der t_test-List-Ausgabe
", df = ", df, ")") # und die df (parameter) aus der t_test-List-Ausgabe
DATEN_BF %>% ## Daten der Befragung mit Ihren angehängten NF
as_label %>% ## die Label für die Grafik verwenden, statt der Werte ("männlich", "weiblich")
ggpubr::ggerrorplot(., x = "Geschlecht", y = "KNTR_m", # die UV ist x und die AV ist y
desc_stat = "mean_ci", color = "Geschlecht", # zeigt die Konfidenzintervalle um die Mittelwerte an
palette = "uchicago", size = .9) + # bei den Paletten können Sie sich umschauen; die hier finde ich nett
labs(x = "Geschlecht", y = "Kontroverse",
title = "Bedeutung des NF Kontroverse nach Geschlecht",
subtitle = "Mittelwertvergleich mit Konfidenzintervall") +
theme(legend.position = "none") +
annotate("text", x = Inf, y = Inf, label = t_Test_Geschlecht_KNTR, vjust = 1, hjust = 1)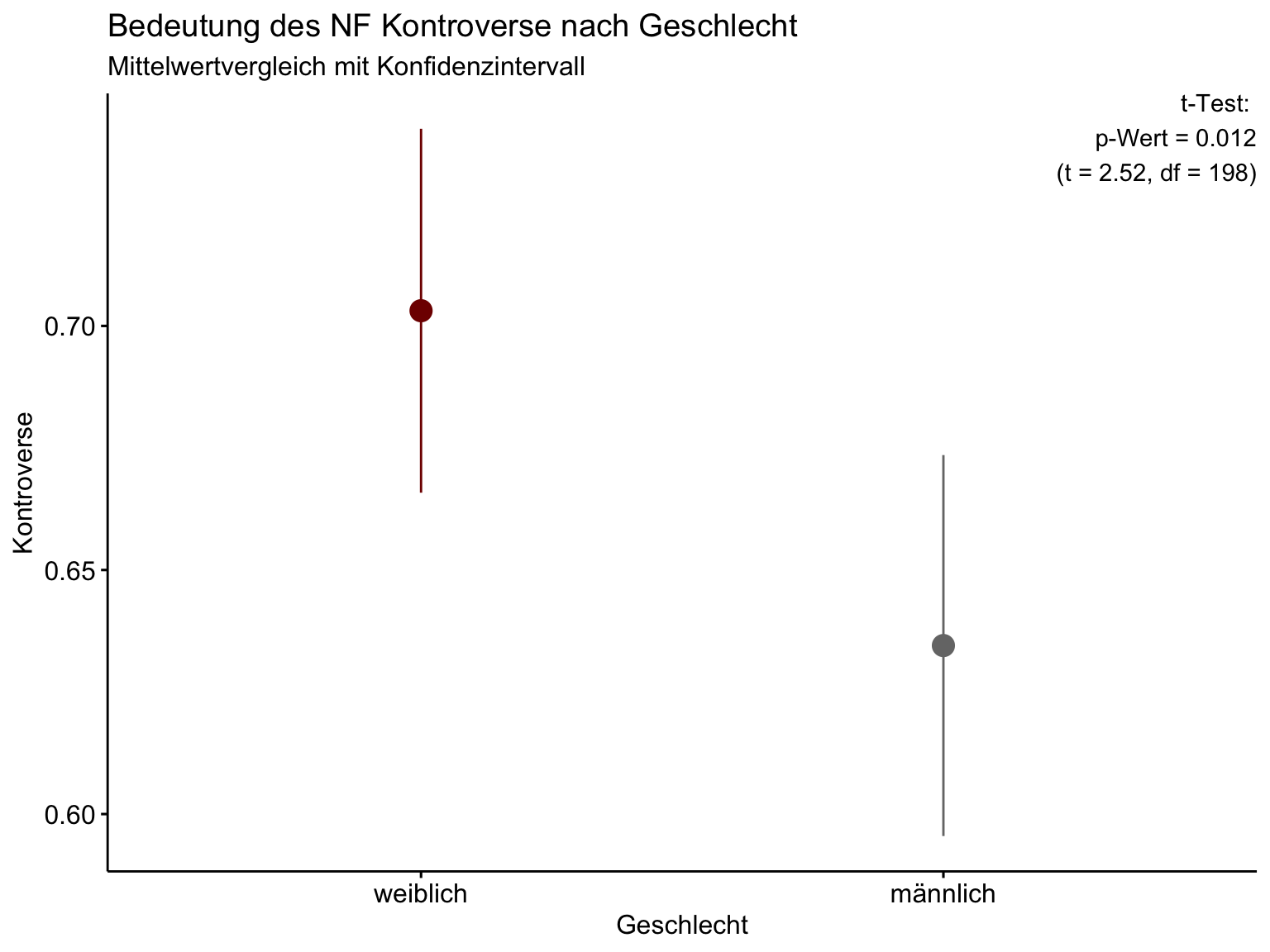
rm(t_Wert, p_Wert, df)
rm(t_Test_Geschlecht_KNTR)7.11.2 Mehrere Gruppen als UV
Hier werden die Mittelwerte für den Nachrichtenfaktor KNTR (Kontroverse) nach Altersgruppen verglichen (gebaut wurde KNTR_m in der Datenaufbereitung siehe 5.2.2). Sie können schauen, ob die Mittelwerte sich zwischen den Gruppen unterscheiden, wenn Sie die Konfidenzintervalle (KI) anschauen. Wenn die KIs sich nicht überschneiden, dann sind die Unterschiede signifikant.
# Erstmal eine ANalysis Of VAriance = ANOVA für die Variable KNTR_m nach Altersgruppen (Alter)
ANOVA <- aov(KNTR_m ~ Alter, data = DATEN_BF)
# summary(ANOVA)
p_Wert <- round(summary(ANOVA)[[1]][1,5],3) # hier wird der p-Wert aus der Summary der ANOVA gespeichert
F_Wert <- round(summary(ANOVA)[[1]][1,4],1) # hier der F-Wert
df <- round(summary(ANOVA)[[1]][2,1],0) # hier die df
### Hier werden die Werte aus dem F-Test in einen Text geschrieben, den Sie in einer Grafike als Annotation verwenden können
ANOVA_Alter_KNTR = paste0("F-Test: \n",
"p-Wert = ", p_Wert, # den p-Wert aus der t_test-List-Ausgabe
"\n (F = ", F_Wert, # den F-Wert (statistic) aus der t_test-List-Ausgabe
", df = ", df, ")") # und die df (parameter) aus der t_test-List-Ausgabe
DATEN_BF %>% ## Daten der Befragung mit Ihren angehängten NF
sjlabelled::as_label() %>% ## die Label für die Grafik verwenden, statt der Werte ("männlich", "weiblich")
ggpubr::ggerrorplot(., x = "Alter", y = "KNTR_m", # die UV ist x und die AV ist y (#Methoden_Einführung! :-)
desc_stat = "mean_ci", color = "Alter", # zeigt die Konfidenzintervalle um die Mittelwerte an
palette = "uchicago", size = .9) + # bei den Paletten können Sie sich umschauen; die hier finde ich nett
labs(x = "Alter", y = "Kontroverse",
title = "Bedeutung des NF Kontroverse nach Alter",
subtitle = "Mittelwertvergleich mit Konfidenzintervall") +
# theme(legend.position = "none") + # mit oder ohne Legende ok lesbar, was Sie schöner finden
annotate("text", x = Inf, y = .6, label = ANOVA_Alter_KNTR, vjust = 1, hjust = 1) # hier wird der F-Test als Annotation eingefügt
rm(F_Wert, p_Wert, df)
rm(ANOVA_Alter_KNTR)